Category: Technology
Trends to look out for in 2016
- Scalable video streaming-as-a-service for “critical” use will become mainstream, allowing several disconnected parties to be connected in real time and allow for the streams to be recorded and audited.
- Collaboration at the tap of a button will become a priority – Moving from an afterthought to a forethought, well integrated as part of a workflow and will be moving away from textual to visual (video) collaboration.
- Predictive analytics with preventive measures around service performance and optimization will continue to be a big ask.
- There will be a larger focus on building product offerings around personal safety/security – i.e. in the case of a disaster/attack, people will want to know that you are safe, what your last location was – or if you are headed to an impacted zone.
- Customers will expect well integrated solutions that provide complete end-to-end workflows with an emphasis on usability.
- Enterprise situational engagement will be an interesting trend where corporations will want closer social engagement for critical events, such as threats, harassment, anonymous tips, etc.
- Connected Health will continue to be an interest for many with a large dependency on EHR integration’s for enterprise hospitals – virtual beds will become more common; however small to medium provider groups will more readily pick up innovative tools showcasing the benefits of technology in providing better care.
eCommerce tooling: Build vs Buy
When you can’t quite find something that fits the need, don’t give in and accept “almost” or “good enough”; don’t settle.
Blank Label needed an eCommerce platform that supported several custom parameters (shirts are complicated). Several were looked at but they didn’t fit; we built our own.
We needed a user experience that allowed dynamic visual updates – theres lots of crap out there, we custom built our own.
We needed to account for manufacturing and our fulfillment, we built our own.
Analytical – several great products out there, we did not build our own 🙂
Email that went out in mass volumes – Thank you sendgrid.
We tried several customer engagement/referral reward solutions, coupon management, gift certificate generation, sales commission – stuff. They didn’t work, we built our own.
We’ve built a lot of stuff – and perfected it. We’ve also learnt a lot about our customers and the way they like to shop and be engaged. We also learnt when to buy and when to build.
There are some exciting things in the pipeline for the stuff we’ve had to build and what we would like to do with all of it.
Stay tuned!
Load testing checkout/sales cart process with loader.io
While its somewhat of a low-priority currently; the developers at BlankLabel have been trying to figure out where and why the worker-process jammed the other day when I hit it with 50,000 requests; and visual studio and their load testing tools will only let them loadtest unit tests to a point… after that you need to bring in a cloud based solution like loader.io from sendgrid to hit you till you pass out.
Most programmers do not think about high availability or how the code will perform under massive loads and many think that its the hardware’s responsibility to make sure that the software is highly available and that its the hardware that should make the application scale and perform but this is just plain wrong. High availability, scalability and performance start at the coding level, when people write code that is scalable the cost for hardware to cover up the problem goes down and at some point, no amount of hardware will save you from bad code that will bottleneck’s you in someway or the other.
Code may behave properly when simple unit tests are run at the pre/post checkin and build phase(s); code may even behave when the QA team hits it with their testing and some in-house load tests but many do not test for high volume/hit routinely because of the effort involved in getting the test’s setup. Lets say you currently have a well functioning checkout process with a simple flow
User login/info -> Product Cart Selection -> Checkout
A new feature requires that the users last 5 orders are loaded into a session; but for some reason the developer decides to load the entire order history data into the session when a user logs in and unknowingly introducing a defect that depending on the order history and number of active sessions, it could cause the worker-process to crash (we wont argue about in-proc session storage here); however this makes it through unit and QA testing and this leads to a longer checkout process, in some cases a loss of session data, or an error; eventually through bug reports / customer support the issue would have been identified and yes it would have been fixed; but this could have been caught by load testing your critical points of success (or failure) like the checkout, signup or login process.
The setup I created for the developers is a bit complicated but to help explain the concept for this post, using BlankLabel as the test subject, I exposed 3 basic web/call points, LoadLogin, LoadCart and LoadCheckout.
LoadLogin uses the user object and uses the data that is passed to simulate a login for the test user using the existing code.
LoadCart uses the Item object and populates a Cart with the data that is passed to simulate a user adding items to a cart.
LoadCheckout uses the Process Order methods to simulate a checkout and sends out an email with the order details (data captured in LoadLogin and LoadCart)
Most do mock test the above with unit testing but the unit testing would not have triggered the performance related issues caused by a high number of active users with large order history data being loaded upon user login.
Using loader.io we are able to create a test that will first hit LoadLogin then LoadCart and then finally LoadCheckout; in each case passing values. Below is a simple screenshot that illustrates this simple test.
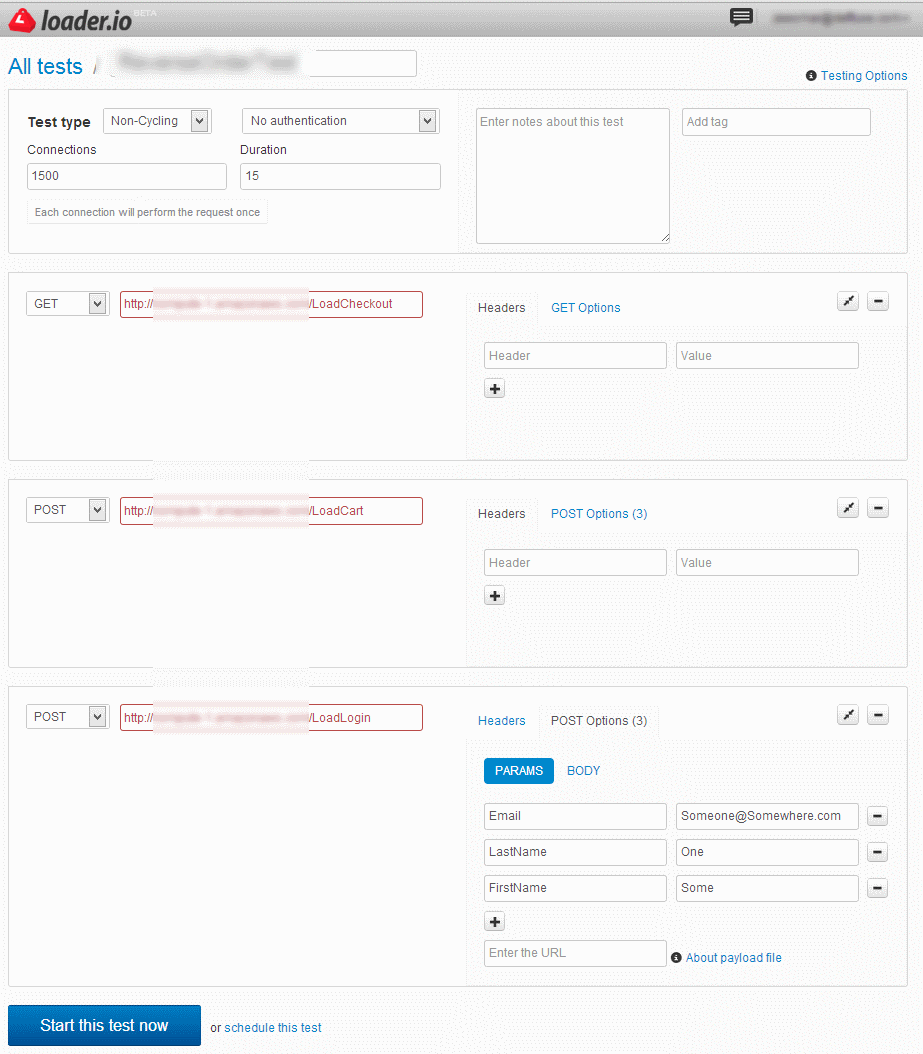 Note: Currently it seems like the URL’s have to be provided in reverse order rather than in-order; so look at the URL list bottom up.
Note: Currently it seems like the URL’s have to be provided in reverse order rather than in-order; so look at the URL list bottom up.
This test will make 1500 connections, each connection will make the URL call (in reverse order) once and hold the connection open for 15 seconds, the connection limit can be increased to 50,000 and you can hold each connection for 60 seconds if you like, but if each connection requires 20kb for its session, you will need the appropriate size of RAM (50000*20KB = 976GB).
If you are sending out emails, you will end up with 1500 emails (it may be smarter to disable the emails in the test and just look at the data stored in the DB post order completion for confirming that 1500 orders were placed with he correct data); as you can guess, I did not click on start this test now for 1500, but I did try it with 15 🙂
Why is any of this important?
In my opinion, services like loader.io help you break things quicker; if you can break things quicker, you can fix them quicker. You can also use it to routinely verify that code/releases you put out do not negatively impact performance by automating load testing by integrating loader.io with your build/test scripts through their API.
Everyone should routinely loadtest their unit tests and plan for growth as I learnt the hard way a couple of years ago…..
Using loader.io to test the cloud
When things are going well we often forget about infrastructure, maintenance, scaling and risk; this is especially when your servers are sitting somewhere in the cloud and that they will “scale” somewhat “automatically” when the services detect that your application needs more resources… Unless you have chaos monkey to keep you on your feet, you are going to have to revisit the past yourself once in a while..
I have been meaning to take a look at what we put together for blanklabel back in 2010 only because I know that there is still a lot more work to be done… but preparing load tests that hit various aspects of the infrastructure is time consuming… you have to capture the flow making sure that you hit the web, database, code, bandwidth and cdn resources where each might already be further cloudified and highly available.
I play with shiny toys every now and then, and recently my shiny toy is loader.io; while blanklabel has been using sendgrid for sending its order confirmation emails since 2010 to users (who eagerly await them). So, what did I gain from using loader.io today? Compared to the other day where I had no problems with a 10k hit (vising 1 static URL); today I tried to hit it with 50k hits, 3 heavy urls per connection… and below are the results.
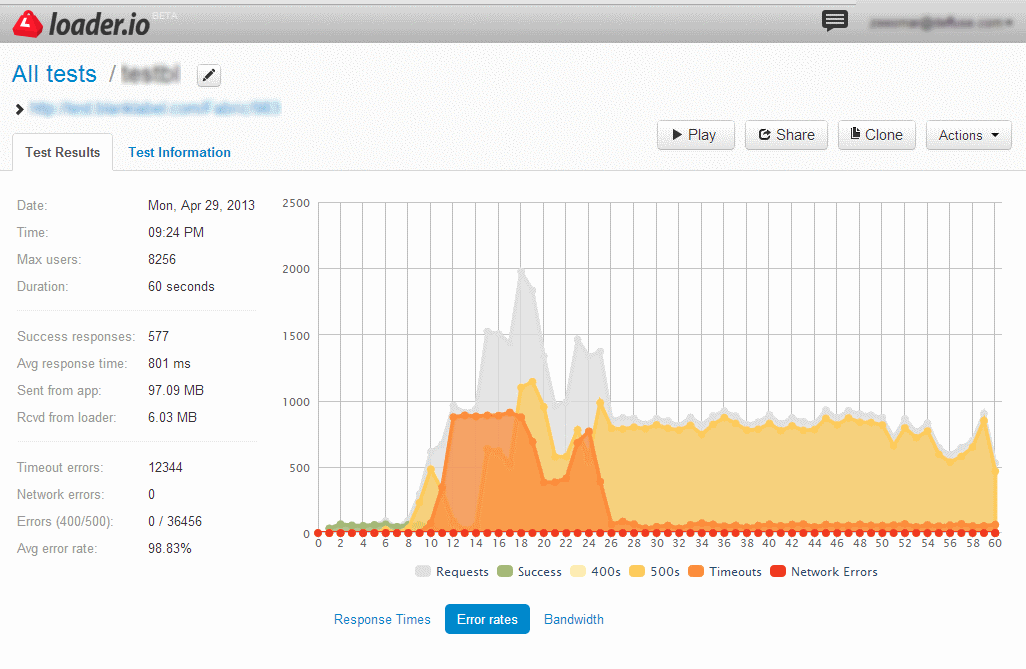
Yes, the test server (I didn’t run this against production) failed at some point and it stopped responding; but its not as simple as that; the infrastructure did not actually fail; the reason why there were timeouts and 500’s were because the worker process got stuck… which means that there is some bad code that can cause a bottleneck before the infrastructure fails, or successfully adjusts resources. Since I had repeated 10k tests a few times before trying a 50k test, its also possible that the cloud admin had already blocked or killed the incoming request which would have impacted my testing… but why leave it open as a risk? n addition to doing a code review, I need to target the workflow correctly; it is quite possible that I did not set things up correctly in the first place.
If you have not checked out loader.io, you should! for me there is a long road that awaits with lots of things to be learnt (and improved).
Creating virtual products on the virtual cloud – Amazon RenderFarm
When we first started talking about what the web based Blank Label experience was going to be like my concern was the visual quality of the product our customers were going to see in the shirt designer. Blank Label allows you to create several thousands of custom shirt design combinations; building a physical product per combination to take a photograph would have been very very very expensive.
Not being able to physically touch the product, and not be able to feel the cloth and not have a good visual of what the product would look like was something were a lot of “not’s” that I was not okay with… so not known anything about 3d modeling nor shirts, I decided to take on the challenge of figuring out how we could come up with a modeling technology that would yield a somewhat realistic shirt… after all, anyone can easily tell a real shirt from a rendered shirt…. right?
The first mistake I made was try to find a company that could create what I needed – there were many; and once I explained the idea behind how I wanted it to work and render, the cost went from $14k to $48k to … over a $100k… yes I know its not cheap to render and design a model, but just because they couldn’t figure out how to automate actions and export clippings (I wont go into details) it did not mean that the client should foot the bill…. anyway., the second mistake I made…. which was the right one… was that I hired a 3d modeler (overseas) to work with me and understand what I was trying to create…. I did not learn much about 3d modeling, but I did learn more than I will every want to about a shirt during this time…. anyway, lets look at what we created back in the day.
Version 1 (2009)

Version 1; wasn’t that bad… but it also wasn’t that good. It did a decent job of showing your fabrics and other selections, but the realism was lost., so fast forward several months we came out with version 2 with a different 3d modeler, and again several months after than version 3 with another modeler., (both below)
Version 2 (2010)

version 3 (2011)

The problem with each (besides it not being realistic enough) was that the modelers themselves did not understand the anatomy of the shirt; and because they didn’t, they couldn’t create a model that behaved like a real shirt. On top of that, they didnt really understand the need and desire behind having things done a certain way because they had never worked on a model that was controlled by code…. at some point we needed to add more features to the shirt, and also, since each modeler we had been through, had a non-automated way of generating renders., it would take weeks if not months to get 10-15 fabrics rendered…. so I went back to the design board, and looked hard…
By now I had some understanding of how the models work, and how things needed to be created., and fortunately for me I found someone who was willing to understand the shirt, and understand the entire process behind what I was trying to do., The best part about this was that he said “I don’t know if i can do this, I have never done this, I don’t know if it will work, but if you trust me and can be patient, I can give it my best shot”
See the image below, they are both zoom shots
 In this image, the one on the left is a picture of a real shirt; the one on the right is a rendered zoom shot of the chest area
In this image, the one on the left is a picture of a real shirt; the one on the right is a rendered zoom shot of the chest area
below is version 4 (current: 2012) of the shirt

With version 4; we have achieved enough realism. There was a lot of attention to detail, both he and I understood every single part of the shirt; how its stitched, how the layers go on each other, etc… and the model we have now., is not just realistic-ish., its also automated… if you head over to Blank Label you will see that there are several rendered views/zooms of the shirt.. which finally brings me to the topic of this post.
We use to render the model on his machines, he had a small network of 3 machines, a decent amount of CPU power, and he would spit out 5 fabrics rendered(each is 86 frames) each day; approx 1.5-2 hours per render. Not that bad… but for us, when we launch new fabric selections, we usually launch 30+ at a time; which means 2 weeks to get those rendered and that is if he isn’t busy rendering other stuff….
We looked at render farms that are out there…. way to over priced and you have to hand over your files… your intellectual property to a third party.. who wants to do that? so we thought that we would give Amazon (AWS) cloud a try…. in theory it sounds great, and there are a few articles out there on how to accomplish it, but they are based on theory…
The best part is that I had no idea what I was doing and it was going to be a challenge to figure it out…after going through the motions and having burnt 20 hours; I can confirm that it works, but it takes time and patience.
To build our renderfarm on amazon AWS using only EC2’s; I simply took a windows 2008 r2 AMI and started configuring it, installing the trial version of 3d studio max and setting it up. Once it was setup, we had the issue of “Who would be the manager”… we decided that it made most sense to have the 3d modeler be the manager so we opened up ports through his firewall into his machine, and viola, the render server connected to his machine and was ready to accept work…. there was just one issue., the files on his machine mapped to a UNC path that did not exist on Amazon…. in hindsight, I would have had him fix it a different way, but we ended up mapping everything to drive Z (took several hours to remap) and once remapped, we used google drive to sync between the amazon cloud instance and his machine; once synced, the server started doing work and started spitting out renders….
Great… but that’s just 1 machine though…
Once the first machine worked, it was pretty challenging to setup a repeatable image; i.e. an image that you could just start, and it would automatically connect to the manager and start doing work. Its not as easy as it sounds, there are permissions that need to be setup, things that need to run as a service, virtual folder to drive mappings that need to be created and the hardest of all, ensure that they connect to the manager. 🙂
I will definitely dedicate a post to walk through an amazon render-farm setup; but I will leave you with this.
What use to take 1.5 – 2.0 hours per fabric, now takes 15-20 minutes with 7 virtual machines; up that to 14 machines and your time decreases by 1/2.
This render-farm allows us to create our virtual products much quicker, virtually on the cloud.
MVC3 .Net Continuous Integration and Deployment in the cloud – Part I
This post builds on my previous post.
The task of getting a MVC3 .Net solution to build in the cloud was not as straight forward as I thought it would be. As I hit roadblocks I googled, and as I googled, I realized that there were many who were trying to do the same and had hit the same roadblocks with no success.
So how does one do CI and deployment in the cloud? Usually people will have a build server somewhere running jenkins, cruise control, hudson, team city… or something else… I wanted to get away from that. I also no longer wanted to manually copy files to the server.. even though that hardly took any time.
Since we already use a few of the Atlassian ondemand products; using Bamboo for automation sounded like a great idea; to use Bamboo for automation, you will also need an Amazon AWS account. The great news is that currently Amazon has a free program for new customers; the not-so-great news is that we cannot completely use the free program because Bamboos elastic agent performs slow and cpu hits 100%… but there is some benefit in being part of this program… so sign up as it offsets some of your costs.
Once you sign up for Amazon Web Services; you need to obtain a few things from the security panel.
1. Get your Access Key pair

2. create/get your certs

Once you have those two things; head on over to the Bamboo administration and configure your elastic bamboo
You will need to enter your AWS Access Key, I changed the shutdown delay to 100, and I opted to enable “Upload AWS account identifiers to new elastic instances.” I don’t think this is actually needed for windows systems (doesn’t work)., but the thought here was that you could start an elastic instance and have it “mount” a specific elastic volume…. this does not work in bamboo for windows systems., but whatever, if you look at the image, you will need to select “files will be uploaded from your PC” and then you can upload your cert key pair; it then uploads and saved it for you. I also opted for Automatic Elastic Instance management, and sent it to passive.. You can change these values if you will be doing a lot more builds; but for starting out and getting things going, the minimum is just fine.

Once that’s done, save the settings; you will then want to view/edit the Image Configuration.
In the image below, you will see that I disabled all the default images and have just one configuration enabled, my own image that I will show you how to create/obtain and get to in Part II; focus on the Default Image EBS x86_64 (windows) stock image, it will be enabled for you by default (this is fine for now). Also notice that the Instance type is set to Large. If you would rather not spend $’s in the setup/configuration you may want to change this to Micro (it will be slower) and its free under the AWS free program.

To change it to Micro, all you have to do is click the Edit link and you can change the value (image below)

Once this is all done; if you just want to check things out and see that they work, you can click on the start instance link in the “instances” page.

Once you click start, head on over to the AWS panel and select “instances“. In the image below, you will see that it displayed an instance, and if you right click, you will have an option to connect, click it

Once you click connect, you will get a popup that allows you to download a shortcut file to remote desktop to this machine; the username is administrator……

So what about the password? how do you get that? clicking the link wont help. for that., you need to head back to bamboo instance management.
The image below shows what you should be seeing, an instance name, and an elastic agent starting or started. Click the instance name

Once you click that, you will get a page that displays the details on the instance; see the image below, the password will be visible in this area, and you can use this to login. Once you are done messing around, you should terminate all instances (esp if you are not using free + micro), you can do that from the instance administration page…
If you try to use this default image as is and configure your build scripts with MS Build, things will not work, MVC3 is missing, a lot of windows updates are missing, nant doesn’t work correctly, and you will want some ftp tool + scripts on there… basically you will want to correct all this, and take a snapshot of the instance (this gives you your custom instance that is updated)…..
The cloud… the sky’s the limit?
Cheesy title? yes….
Every now and then; I end up either being part of a “Cloud” discussion or hear people talk about the “Cloud”… interestingly, majority of these people do not know that the “cloud” is not new… its old., yup., its not a new concept., and if you are a techie, you will know what I mean when I say “The cloud has been there for YEARS!!!”… but if you are hung up on marketing and sales, google around and see the true history of what the cloud is made up of…..,
So why today? why is the cloud “new” today? any why the “Cloud”… well., Ill take a cheap shot and say that these terms., “Saas, Paas, Iaas…. -aas” got boring….. but what I will follow that cheap shot up with is that.. its not entirely true… there is something that the “cloud” brings… and that is “encapsulation”.
From wikipedia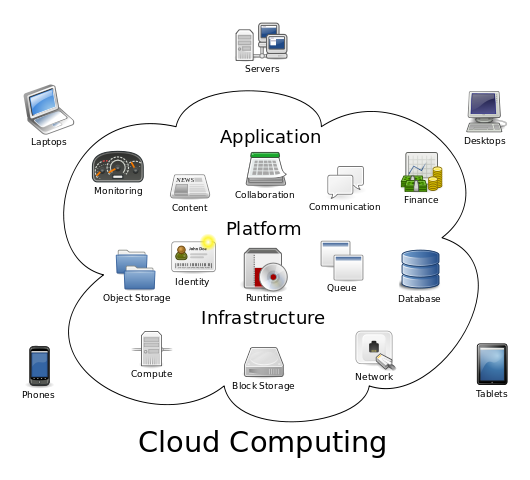
So what “cloud” does provide is the delivery of “computing” as a service., and computing., encapsulates everything..
The Cloud is just the beginning in a shift in paradigm in how we expect to do things; several years ago, I wanted a “light weight LCD with a built in wifi chip and a minimal processor that allowed remote view”… why? well…. If i had this, i could have a very powerful server, somewhere in the garage, running 4-5 virtual machines and I could give everyone in my house a wireless LCD that connected to these VM’s…. so this was back in the early 2000’s…. far far far away from the iPads and googls chrome books… but this base idea was not original… I simply extended the offering of Motorola’s tough book offering which came with a wifi tough screen (that paired to the tough book).. This would allow users to leave the base in the car and walk around with a rugged LCD (touch screen)…. so… if you go back to the extension… that I was hopeful for… you end up with what the cloud can offer.
Imagine a time where you no longer needed to purchase a “fast processor” or needed to waste desktop space on desktop hardware… take it to the next level, imagine enterprise’s where you do not have to rely on IT to make sure they have the staff and experience to cover your needs, perform upgrades…. Its a shame that some of us still run windows XP on our brand new laptops, or have to use Microsoft Office 2003 today!
The cloud is all around us; Google being one of the most obvious cloud initiatives with their offerings, and other offerings such as prezi, dropbox, confluence, salesforce, rackspace, amazon, zoho…. and so on… the future of all these efforts will be cloud api’s and how we enhance and extend the offerability to a larger audience…
eCommerce Tech- When sucess is the reason for failure
Success is always welcomed; we always work towards success, and preferably in most cases we can track towards it and see it coming…
But what do you do when success comes and you are the least bit prepared?
In the eCommerce world, your ability to evolve will make or break you. If you don’t rush to ensure you are prepared, you will end up with failure. I learnt an important lesson in eCommerce and startup almost a year back, may 2010.
Most tech based startups, start lean, and thats the appropriate approach. You do not want to go out and get dedicated hosted, or even get on a cloud host that costs a few hundred $’s a month when your revenue is $0 or already in the negative.. on that train of thought…
We were hosting our Blanklabel website on a shared host. Our provider was discountasp.com and I had (and still do) used them for years for many other projects/websites. I have always known the benefits and drawbacks of using a shared host…. and at 60k visitors per month and no set bandwidth limits, it was a great home for a “start up”….
That was until the New Your Times published an article on us.
To be fair, I did know that we were getting an article published in NTY; but it was a day or two before and there wasn’t much we would have done in preparation for it mainly because we did not know to expect. Our website was functioning, the order and payment system was fine, everything looked good…
Within a few minutes of the article showing up… we went from “functioning perfectly fine” to the brink of failure! How? Why?…. I live in CA so below is a time-log in PST of the sequence of events..
3:00 AM – I was coding Away… decided I needed to get some sleep so I closed shop…
3:30 AM – My phone rang, went to voice mail, woke me up,
3:35 AM – Checked my email, saw some questions about performance, looked at the website, seemed fine, sent an email in response, sent an email to discountasp went back to sleep
4:30 AM – Phone ran, answered, heard something like “It seems to be fine on my end, but customers are saying that the images are not loading”., I said “How many? just a couple? Call me back if its more than couple, could just be their connection, its working fine for me as well”… checked email, discountasp responded with the same “looks good here”, emailed them again “We are getting more complaints”.. back to sleep
6:00 AM – Phone rang again, Panicking person (you know who you are) on the other end “I have 22 chat sessions open with customers who are trying to buy, there is something definitely going on”.. This time, I got out of bed, I cleared cache, refreshed the pages a few times, tried to place and order, and there it was, random images were missing, email went out to discountasp again..
6:15 AM – I decided it was time to start looking at the logs… and there it was… As people started their morning on the East coat and were looking at their NYT print and web… our hits were rising… we had gone from a few hundred per day… to 35,000 per second… yes PER SECOND.
6:15 AM – Emailed discountasp again! asking if we could increase shared resource or get some sort of load balancing and pay for multiple servers… and also decided it was time to look for a Plan B
6:16 AM – Started looking for my Rackspace contact….
6:17 AM – Started to chat with Rackspace
7:00 AM – Signed up for Rackspace Cloud
7:19 AM – Started to download the current discountasp FTP snapshot
7:20 AM – 6 month old daughter woke up, so I was entertaining her while i did the rest below…
7:30 AM – Response from discountasp “Yea, we cant help you”…..
7:35 AM – Started to prepare a mental migration plan.. aka Plan B…
7:40 AM – Plan B was ready! Created SSL request at RackSpace, MS Sql server provisioned
7:45 AM – Download database backup file
8:00 AM – Restored Database file at RackSpace… Decided I should account for the orders that will continue to go over to the discount house so that no orders are lost and that I can migrate them over later… So I put in a 1500 order jump in the identity seed
8:XX AM – The rest of this hour went towards uploading the website to Rackspace,updating code to ensure that things worked fine on Rackspace, doing a few test runs…..updating DNS, generating and applying SSL,
9:XX AM – Started seeing orders come in on the new Database…. not just 1 or 2 here and there., but 15-20 every few minutes minutes. Was still chatting with Rackspace support to see if we could get some sort of stats, but since we had just signed up, it was not yet setup.
10:00 AM – Started to see discountasp log show traffic had reduced, server was now able to process requests that it got while the DNS updated globally.
10:XX AM – Declared Victory, while all the above was going on, My daughter was entertaining me.. or was it I who was entertaining her?…
11:00 AM – Continued to see things progress… orders still coming in… in hundreds… Called it a day for now… needed a break from this..
11:30 AM – Some more emails came in from discountasp ….. I wasn’t too happy with their lack of customer service and commitment… I guess the name does fit it well… its a discount store.. nothing compared to Rackspace’s fanatical customer support… I would not say they are really that “Fanatic”.. but… its better than discountasp and they are usually helpful.
6:XX PM – Due to the large # of orders, outgoing emails got blocked because the Rackspace servers saw it as SPAM/Flood. after an hour or so of going back and forth, Rackspace unblocked the email and thousands of emails went out to customers.
———–
2:00 AM – Discountasp hosted site was at 0 hits; Did a global DNS check, found all routes leading to Rackspace host.
2:XX AM – Started coding scripts to bring in the orders that ended up going to discountasp servers while DNS was still updating
3:XX AM – Executed the scripts after verification.. was impressed to see that my buffer of 1500 served me well., we had 1393 orders that ended up saving on the old database… once these were broight over with the same Order Id we had a gap of just 107 orders!
4:XX AM – Realized that I forgot to put in a buffer for the User Id, had to resolve this as we now had two users with the same User ID’s because of the split servers
5:00 AM – Emailed out the #’s of shirts we sold to the team!…
———-
7:00 AM – “Shut down the website, we cannot process any more, we are over capacity”…. I will leave this one for another day..
———-
In the time-log above, I have highlighted take-aways in bold that will help you prepare and execute a “Live Migration” from one host to another host AND ensure that all your data comes with you, with no additional negative impact to your customers. Today, we are still with Rackspace and are content with their service… We have however grown and believe we are ready to take the next big step in cloud hosting.
This blog post is just one of the many examples where potential success can take you down if you do not know how to prepare, execute and evolve in real time.
You are a worthless customer
Artscow.com, Thank you for telling me how worthless I am and giving me something to write about.
While this post is a dedication to artscow.com, the major focus of this post is “What is a customer worth to you”.
I am aware that there are more than a handful metrics and formulas you can use to figure out a $ amount; but this post is directed more towards the ethical and monetary value of a customer.
So let me start with a series of events…. Which were actually related to my wife’s interaction with an ecommerce purchase:
We have been long time customers of shutterfly, we love their customer service, product quality and the variety of products and services they offer…
Shutterfly does entice us with special offers and discounts and many times we pay full price for their products, which compared to professional studio and/or printer are a steal with as good or greater quality. Whenever there is a need, we have obtained products from them…
However; every now and then, you come across an offer that doesn’t cost you anything, and you say why not… One of these offers was artscow; they were offering 30 8×10 prints for free; all you had to pay was standard us postage, roughly $3.
My wife ordered the prints; a decent looking website.. The eCommerce/cart was slightly underpowered compared to shurterfly (boy is that an understatement) but it was a Fairly painless process.
A week or so went by and the prints showed up in the mail. We noticed that these shipped out of china (nothing wrong with that) and upon opening then, the print quality was decent; I.e nice color and gloss… However upon inspecting the images, the pictures were cropped left and right. From the 15 prints, 2 were usable.
My wife got on gmail and contacted customer service; a day went by and the response we got was instructions on placing items in cart and ordering them. None of the content in the response addressed the issue with the print.
Now I had to get involved; I took pictures of the pictures and emailed them over along with what it should have looked like. Also took a screenshot of their webpage that showers thumbnails of what was being ordered.
What I was expecting was a “Thank you for the details, please use this coupon to reorder your prints. While reviewing your images, we notices that the image is slight larger than what 8×10; even though it would have fit as the proportions were correct, out tool does not resize/shrink. Hence the cropping”…..
What I got was, “you didn’t adjust the image, so your got that”..,., and that was it…
I guess, we have been spoilt by shutterflys tool that notified you of any potential issues you may run into if your image is larger than the print or the image resizes, or crops.. but is that really our fault?
Here is where my “You are a worthless customer” statement ties in.
1. We were given FREE prints
2. We paid about $3 in shipping
How hard would it have been for artscow to say “Let us fix your experience, here is a coupon for another set of free prints” and maybe they could have even thrown in a “and you don’t even have to pay for shipping this time”… keep in mind, we still had coupons in our account for free prints which artscow.com would have been aware of… so I guess, we were not even worth $3 to them 🙂 what does it tell you about such a vendor?… so what is their official policy? “ArtsCow.com offers 30-day money back guarantee on all products. If you would like to return or exchange an item, please contact us to fill out a request form, and we will instruct you on how to send the item(s) back. Please keep in mind, shipping charges are not refundable”…. go figure…
Let me compare this to similar situations with shutterfly, at one time we ordered prints using low res images instead of the high res ones. When they got printed, the pictures were pixelated, obviously customer fault; however, shutterfly reprinted and shipped for free! I believe our order was worth $65; doing a comparison on “how much a customer is worth” I would have to say that we were at least worth the $65…. Now should the order have been $600 and it had been customer error; I do not know if shutterfly would have given us the same “let’s fix it for you”… eventually it tapers off and vendors will only pay so much to hold onto customer loyalty… however, their policy “If, for any reason, you’re not happy with a purchase, we’ll replace your order, at no charge, or give you a full refund.”….
Enough about shutterfly; let’s talk about Zazzle.com. We purchased a Groupon for $50 for $25; went online, customized some invites, ordered the invites; got them in the mail; somehow the “customized text” was replaced with the “generic text” that was shown as an example.
1. Customer error? No, and even it was….
2. Cart/Website should have caught the issue as no one would be buying customized invitations and keep the generic/sample text
The total order was worth $87; I chased Zazzle customer service down on twitter and had them help me with an emailed request to customer support. We got our Groupon certificate replenished and balance refunded and we placed our order again. Customer worth? $87 in this case…. and actually, if you look at Zazzles policy “If you don’t love it we’ll take it back”..
Now let me mentioned another eCommerce vendor that i actually know more about, and that is blank-label.com.
I know that at blank-label.com we care about customer satisfaction and loyalty, on the front page currently we have “Our Custom Fit Guarantee You will be completely satisfied with your custom fit dress shirt. If not, we’ll take it back and try again–free of charge.”. We toyed with 100% refunds in the beginning and then moved onto free remakes and we have been thinking of going back to 100% refunds or remakes. We moved away from 100% refunds was because we really wanted to do a good job of making sure that we met customer expectations and simply giving the money back wasn’t cutting it for us; if we still messed up after the 2nd try, we do refund the $’s and if someone really doesn’t want a remake, we refund in those cases as well… it’s just not a published policy 🙂
What is blank-labels customer worth? I have seen transactions in the $300 range been credited back to customer service; if you have not yet tried a custom shirt from blank-label.com I suggest you give them a try.
In summary, Customer satisfaction brings customer loyalty; if you do not care about your customers, they will not care about you…. especially if you make them feel worthless.
