Tagged: loader.io
Load testing checkout/sales cart process with loader.io
While its somewhat of a low-priority currently; the developers at BlankLabel have been trying to figure out where and why the worker-process jammed the other day when I hit it with 50,000 requests; and visual studio and their load testing tools will only let them loadtest unit tests to a point… after that you need to bring in a cloud based solution like loader.io from sendgrid to hit you till you pass out.
Most programmers do not think about high availability or how the code will perform under massive loads and many think that its the hardware’s responsibility to make sure that the software is highly available and that its the hardware that should make the application scale and perform but this is just plain wrong. High availability, scalability and performance start at the coding level, when people write code that is scalable the cost for hardware to cover up the problem goes down and at some point, no amount of hardware will save you from bad code that will bottleneck’s you in someway or the other.
Code may behave properly when simple unit tests are run at the pre/post checkin and build phase(s); code may even behave when the QA team hits it with their testing and some in-house load tests but many do not test for high volume/hit routinely because of the effort involved in getting the test’s setup. Lets say you currently have a well functioning checkout process with a simple flow
User login/info -> Product Cart Selection -> Checkout
A new feature requires that the users last 5 orders are loaded into a session; but for some reason the developer decides to load the entire order history data into the session when a user logs in and unknowingly introducing a defect that depending on the order history and number of active sessions, it could cause the worker-process to crash (we wont argue about in-proc session storage here); however this makes it through unit and QA testing and this leads to a longer checkout process, in some cases a loss of session data, or an error; eventually through bug reports / customer support the issue would have been identified and yes it would have been fixed; but this could have been caught by load testing your critical points of success (or failure) like the checkout, signup or login process.
The setup I created for the developers is a bit complicated but to help explain the concept for this post, using BlankLabel as the test subject, I exposed 3 basic web/call points, LoadLogin, LoadCart and LoadCheckout.
LoadLogin uses the user object and uses the data that is passed to simulate a login for the test user using the existing code.
LoadCart uses the Item object and populates a Cart with the data that is passed to simulate a user adding items to a cart.
LoadCheckout uses the Process Order methods to simulate a checkout and sends out an email with the order details (data captured in LoadLogin and LoadCart)
Most do mock test the above with unit testing but the unit testing would not have triggered the performance related issues caused by a high number of active users with large order history data being loaded upon user login.
Using loader.io we are able to create a test that will first hit LoadLogin then LoadCart and then finally LoadCheckout; in each case passing values. Below is a simple screenshot that illustrates this simple test.
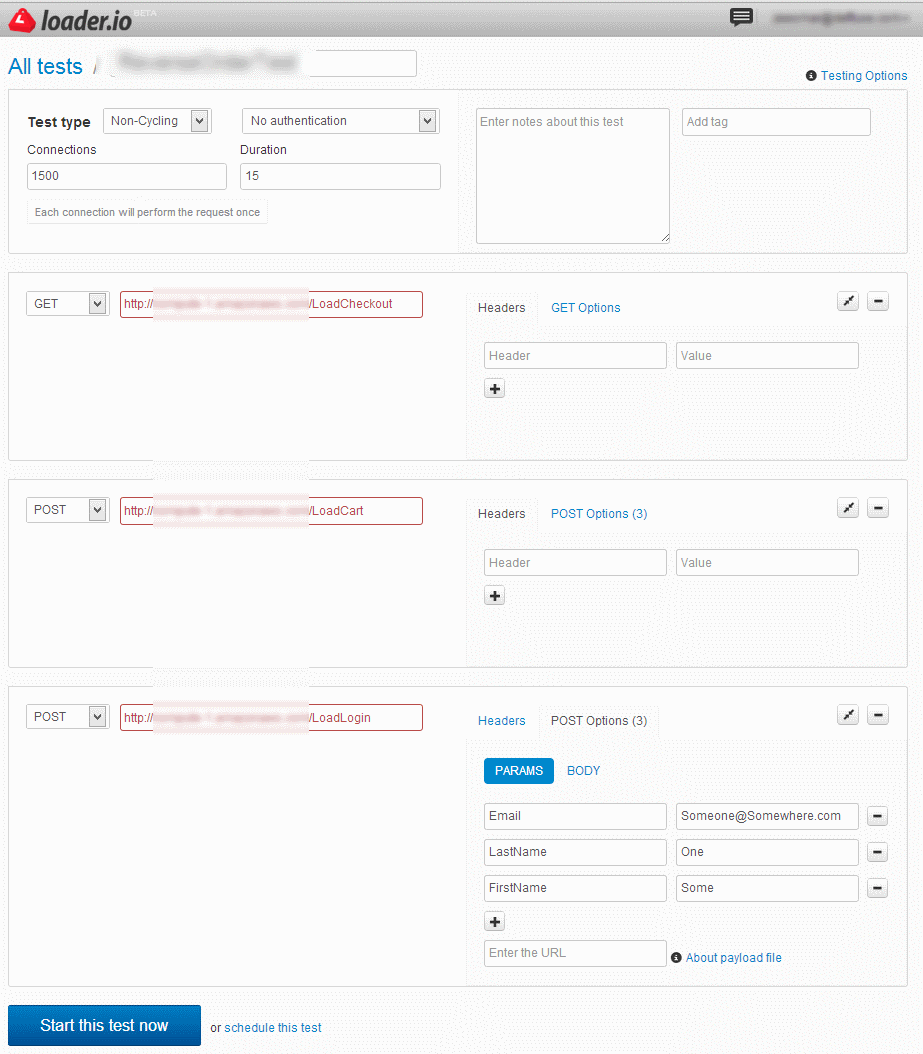 Note: Currently it seems like the URL’s have to be provided in reverse order rather than in-order; so look at the URL list bottom up.
Note: Currently it seems like the URL’s have to be provided in reverse order rather than in-order; so look at the URL list bottom up.
This test will make 1500 connections, each connection will make the URL call (in reverse order) once and hold the connection open for 15 seconds, the connection limit can be increased to 50,000 and you can hold each connection for 60 seconds if you like, but if each connection requires 20kb for its session, you will need the appropriate size of RAM (50000*20KB = 976GB).
If you are sending out emails, you will end up with 1500 emails (it may be smarter to disable the emails in the test and just look at the data stored in the DB post order completion for confirming that 1500 orders were placed with he correct data); as you can guess, I did not click on start this test now for 1500, but I did try it with 15 🙂
Why is any of this important?
In my opinion, services like loader.io help you break things quicker; if you can break things quicker, you can fix them quicker. You can also use it to routinely verify that code/releases you put out do not negatively impact performance by automating load testing by integrating loader.io with your build/test scripts through their API.
Everyone should routinely loadtest their unit tests and plan for growth as I learnt the hard way a couple of years ago…..
Using loader.io to test the cloud
When things are going well we often forget about infrastructure, maintenance, scaling and risk; this is especially when your servers are sitting somewhere in the cloud and that they will “scale” somewhat “automatically” when the services detect that your application needs more resources… Unless you have chaos monkey to keep you on your feet, you are going to have to revisit the past yourself once in a while..
I have been meaning to take a look at what we put together for blanklabel back in 2010 only because I know that there is still a lot more work to be done… but preparing load tests that hit various aspects of the infrastructure is time consuming… you have to capture the flow making sure that you hit the web, database, code, bandwidth and cdn resources where each might already be further cloudified and highly available.
I play with shiny toys every now and then, and recently my shiny toy is loader.io; while blanklabel has been using sendgrid for sending its order confirmation emails since 2010 to users (who eagerly await them). So, what did I gain from using loader.io today? Compared to the other day where I had no problems with a 10k hit (vising 1 static URL); today I tried to hit it with 50k hits, 3 heavy urls per connection… and below are the results.
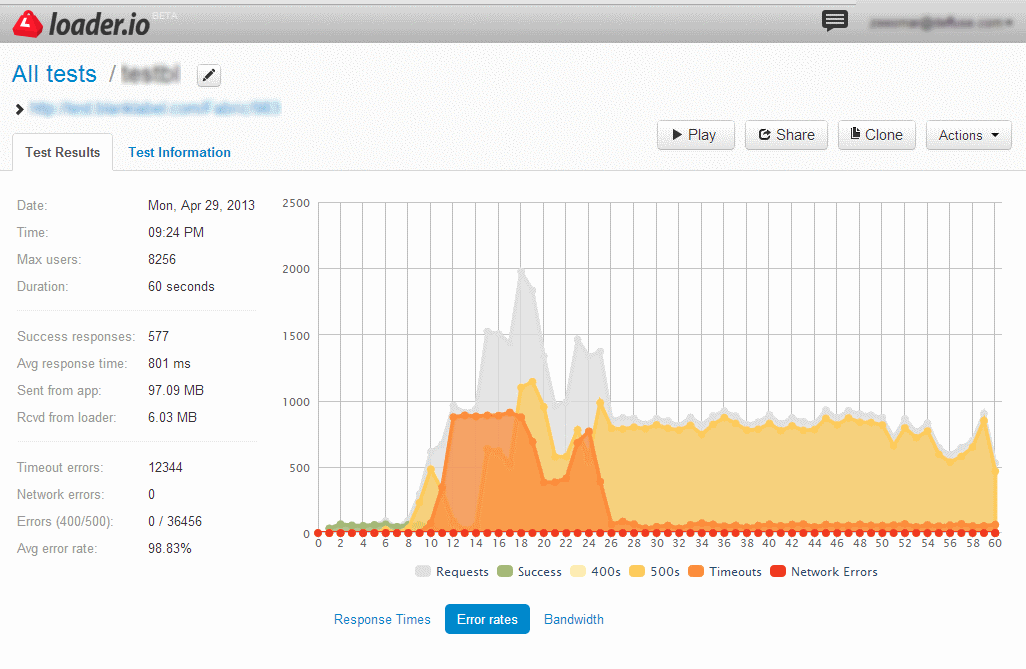
Yes, the test server (I didn’t run this against production) failed at some point and it stopped responding; but its not as simple as that; the infrastructure did not actually fail; the reason why there were timeouts and 500’s were because the worker process got stuck… which means that there is some bad code that can cause a bottleneck before the infrastructure fails, or successfully adjusts resources. Since I had repeated 10k tests a few times before trying a 50k test, its also possible that the cloud admin had already blocked or killed the incoming request which would have impacted my testing… but why leave it open as a risk? n addition to doing a code review, I need to target the workflow correctly; it is quite possible that I did not set things up correctly in the first place.
If you have not checked out loader.io, you should! for me there is a long road that awaits with lots of things to be learnt (and improved).
