Category: SDLC
Blended Innovation Life Cycle – Readiness Score
This post looks at defining a blended innovation life cycle & an innovation readiness score – It builds on the previous post on Blended Innovation Model
Are we there yet?
Sharing progress on a revolutionary (or even an evolutionary) innovation becomes a challenge when not everyone speaks the same language – Core teams have worked the way they have for years and the MVIT operates with a completely different rule book (or at times; no rules).
A quick reference to the differences between the Core and the MVIT from a previous Blended Innovation Model post:
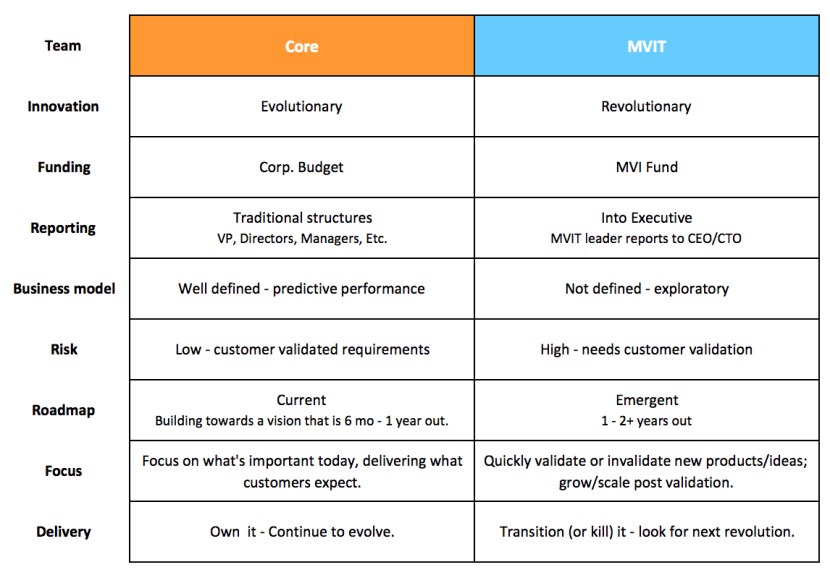
You are here (X)
Core teams generally function as a well-oiled machine and follow a SDLC that covers some, if not all of the following:

When looking at the interplay between the Core and the MVIT in a blended innovation engine we should look at how the MVIT lines up its efforts in relation to the existing SDLC (the well-oiled machine everyone is used to); Ideally we end up with two independent cycles that intersect or allow the movement (of products from the MVIT into the Core).
If we list out the various stages across development and implementation and assign responsibilities in the context of Revolutionary vs. Evolutionary innovation projects, we get a holistic view of where and when the MVIT is engaged.
For revolutionary/exploratory innovations – the MVIT (only) will start with POC’s and pilots in a vacuum to prove the value, and once it does, it will look at integrating with core to release the product in a limited scope for additional customer validation. Once larger validation has been performed the product will move to the core team for general availability. The matrix below helps illustrate the primary team(s) responsible for the slot/phase.

For Evolutionary/ Growth / Acceleration innovations – the idea has already been validated and the primary purpose in MVIT’s involvement is to help rapidly pilot and accelerate the development so that It can be integrated and added without negatively impacting the product roadmap. The Pilot and Limited stages are identical as there really isn’t a pilot phase. Once larger validation has been performed the product will move to the core team for general availability. The matrix below helps illustrate the primary team(s) responsible for the slot/phase.
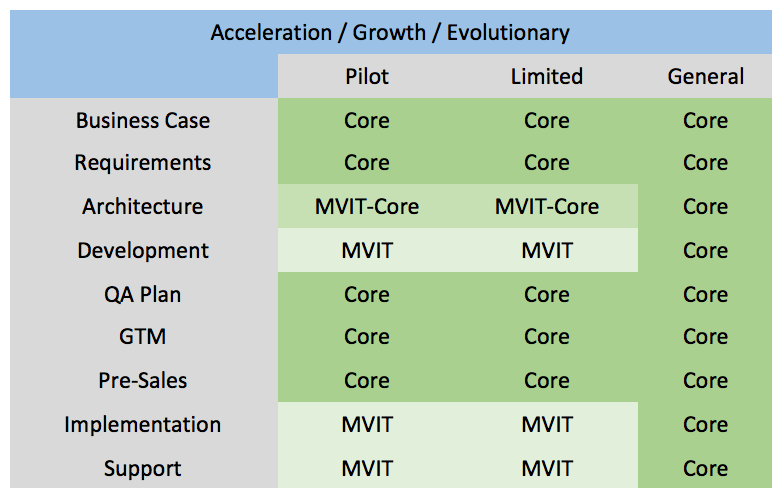
Blended Innovation Life Cycle
Based on MVIT’s roles and efforts above – we can summarize and group MVIT’s role and efforts into 4 major phases and refer to it as the Blended Innovation Life Cycle (BILC):

MVP
During the MVP phase, the MVIT is focused on three progressive stages:
- Inception: Defining a very vague or high level idea that might seem like a good fit for the MVIT to work on.
- Fit: Refining the very vague/high level idea to answer “Does it fit?” – if we were to build this, can it integrate with the core product? How would it integrate? The focus here is on reaching an absolute Yes/No assessment on fit regardless of answering things like “when does it fit” or “how long will it take”.
- Pilot: MVIT will move forward and hack together a pilot that can be used for internal demos to showcase the idea – majority of the work is likely hardcoded or manually configured – the goal isn’t to make a finished product, but rather quickly show something that can help explain the idea and value add
It’s very likely that the MVIT never gets to stage 3 for majority of the ideas – but for the ones that do make it to the third stage – they then move to the next phase: “Viability”.
Viability
In the “Viability” phase the focus is on (internal) Customer Validation – the MVP is shown to the product team and other product roadmap stakeholders (like sales leadership) to assess business value. The product team would look at how the idea would enhance the product roadmap and would help define how the product would integrate with the core. A decision is made to move forward and to introduce to additional customers via limited availability.
Production
In the “Production” phase, the focus is around Limited Availability stage – the MVIT works with the Core Product team to build a closer integration where architecture, integration approach, development, QA implementation and pre-sales plans are defined, development and implemented (by MVIT and Core). For customers who enter limited availability, the MVIT is responsible for supporting its product(s) where MVIT will not only provide front line support where needed, but also deploy and maintain deployment environments.
Scale
The “Scale” phase is focused on two final stages
- Transition: where the product and its support is transition to the core team – all artifacts, such as code, support guides, implementation guides, etc. are documented and handed over.
- Mainstream deployment: where the core team works with operations and support team to take over deployment and support.
Summary
By defining the “BILC” in the manner we did – where the core team becomes an integral part of the innovation directly after the pilot, we help implement a process that allows a natural alignment to the Core’s SDLC and we don’t end up with a team that’s releasing under-baked products that don’t integrate well with the core product.
We can also number each stage in the “Blended Innovation Life Cycle” to obtain an “Innovation Readiness Score” and we can then use both the score and the phases to help report on the readiness of an innovation and figure out where we are and what’s next.

RAPID Agile: Customer Focus – Defect Management
Before we dive back into defining an approach that mixes Product and Custom focus, we should probably ask “How does one focus on the customer?”
In an ideal world there are no defects; but since there are, and customers expect them to be resolved, an ideal approach balances itself between being proactive and reactive; proactively resolve reported/discovered defects and appropriately manage escalations. On the surface, one focuses on the customer by making sure that the defects are fixed before a customer reports them and if a customer reports them, they are addressed promptly (top priority of course) and the customer is satisfied – below the surface, defect management and prioritization play an important role towards our customer focus as this tells us how soon we can (and will) actually resolve defects.
The list below doesn’t capture all possible approaches in resolving defects; it captures approaches that I have had some experience with (I recommend that you certainly do not try the first one):
Don’t resolve them- Push the defect to the original developer, or the developer most familiar with the functionality for resolution.
- Allocate time for the first available developer to pull a defect in and resolve.
- Have a defect duty rotation where a person (or team) resolves only defects for a time period
- Have a dedicated team for defect resolution.
- … Some other create ways to resolve reported defects..
Always push to most familiar
Pushing the defect to the most familiar sounds like a great idea and in many cases it is because the one most familiar would be able to resolve quickest and positively impacts customer experience. The issue with this approach is that the most familiar person might be involved with something that has a higher priority than this defect, or is out on PTO and would not be able to resolve for another 2 weeks. Let’s say it takes someone familiar with the code to resolve in 1 hour but takes someone not familiar with the code 6 hours. If the defect goes to the person currently tied up and is most familiar, the customer will have to wait a minimum of 2 weeks + 1 hour; however, if it goes to the person not currently tied up and is least familiar, the customer will have to wait a minimum of 6 hours. Being collaborative and available for the team may improve the turnaround time on average, but a hard coded “always send to the one who created it” may not be the best approach.
Allocate time to pull
Allocating time towards the end of an iteration, development or whatever, towards “defect resolution” allows the team to first get the scheduled work out of the way, and “if” there is time, someone may pick something up from the backlog of defects. The issue with this approach is that if the development cycles are fully booked (maybe there is a hard date) and there is any risk or complexity that might lead to developers putting in all they have to meet the delivery; defect resolution gets thrown on the back burner. In most cases where the approach is “allocate time to pull defects”, the unspoken rule is that new products come first, defects second – unless; where the “unless” is for escalations and chaos/fire-fighting instances. For agile teams, if the time allocated towards defect resolution does not change from sprint to sprint, then there is no impact to velocity; however, if the time allocation is not fixed the velocity can get impacted depending on how much time is spent on defect resolutions (usually hours) vs. features (SP’s)…. You could estimate defects in story-points but this can lead to additional issues that will need to be worked out… i.e. do you really want to hold a sprint back? etc..
Defect resolution duty rotation
For a given time (usually the span of a sprint) a developer within a team, or a whole team themselves will be on defect resolution duty; once the time span is over, someone else (or a different team) takes on defect resolution duty and so on. This helps cross-train and helps make everyone familiar with the code base. It can also help improving code quality since everyone is learning from everyone’s mistakes and provides a great collaboration platform; while it does have some great benefits it does introduce some challenges. A significant issue is that developers and teams lose traction as they switch focus from “new product” to “old product”; the interruption can cause a delay since the developer(s) will need to get back to where they were after the rotation is over. For organizations that have many teams or larger teams this may be less of a concern since the rotation might happen every few months; but even then, when it does happen it does have a negative impact.
Dedicated team for defect resolution
The thought on this one is that if there is one team solely focused on supporting “released software” (defect/engineering sustaining team) and other team(s) focused on creating “new software” (Feature teams) that you end up with a two-tiered development approach where both the product and the customer can be focused on. The feature (new software) team is rarely impacted by defects from the “live” world and they can always focus on delivering new product; the defect/engineering sustaining team is dedicated to resolving defects and is not tied up with new features. The issue with this approach is that no one aspires to be a “defect fixer”, developers want to “develop” new and innovative “features” (or at least I did); It is possible to make this work if more attention is given to down-time cross-training, root cause analysis, collaboration, role rotations, etc… (I have seen teams evolve this approach into a “defect resolution duty rotation” approach)
In addition to the above, there can also be hybrid approaches that mix various approaches, i.e. defect resolution duty rotation with an added “pager duty” where someone (not on defect duty) is on-call but in general there is no “incorrect approach”; however:
Any approach can become incorrect when developers are forced to accept an approach that they do not agree with (or understand).
Any approach that is going to be implemented should be discussed with the teams that will be implementing it, focus on and explain the “why”. When an approach does not work, try to adjust it or try something else!
“if the code repository is an “elephant” and new code is peanuts being fed to this elephant by the other guys, then I am always cleaning up after the elephant; who wants to be a shit cleaner forever?”.
RAPID Agile: Focus on Product and Customer by mixing Scrum and Kanban – ScrumBan
We are usually torn between building more “product” or satisfying the “customer”.
Prioritize Customer (maintaining product)
Fix and release to save the world
Prioritize Product (building more product)
Plan and build to a schedule
When you focus on product, you have a certain “amount” of product that needs to be built within a sprint (time box); you can plan for fixes by leaving some room for the defect backlog, but features come first – then come fixes, and the work is usually fixed where people know what they are working on for the sprint. In this scenario most will usually package after the sprint is over (test and release)
When you focus on customer, you have to fix and get the fix out the door ASAP. Priority is given to the most critical fix and/or customer and things will be packaged (test and release) as soon as appropriate and/or possible.
Some solve this by having a sustaining engineering team, but who really wants to only fix defects?; others use a mix of cross-functional or functional teams and adjust as needed, but this can be disruptive.
If you chose to “adjust as needed” (be agile) you will introduce some chaos every now and then but this can be minimized by having “plan of action”. How you adjust as needed and what type of “plan of action” you need also depends on what type of process you follow and what your focus is; is your culture focused on product? or is your culture focused on the customer? Depending on whom you ask (their role) within an organization, you may get different answers.
If you follow “Scrum” then your work queue is mostly “push” defined, where work is planned and pushed into a sprint/iteration before its worked on.
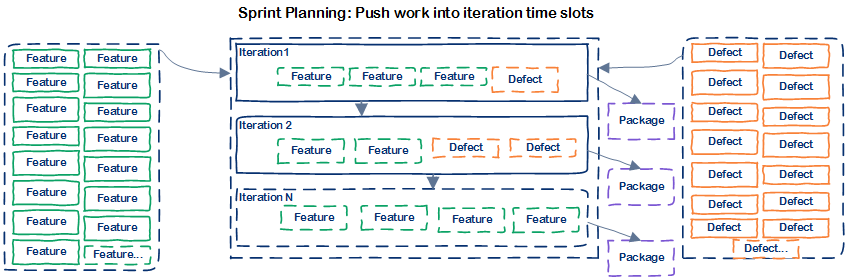
If you follow “Kanban” then your work queue is mostly “pull” defined, where work is pulled and worked on.

In an ideal world, one would have a process that allows the focus on both, the product and the customer. A process that allows you to “build what you say you will build” but also allow you to focus on “what is important right now”; such a process would mix Scrum and Kanban, giving you, ScumBan. The idea of a Scrumban is not new; there are books and many talks/posts regarding this. How Scrum and Kanban are merged together depend on the person who is cross-breeding the processes and what problem(s) they are trying to solve; I named my implementation “RAPID” for “Real-time Actionable Prioritized Individual Delivery”.
In my next post around RAPID, I will go over some examples that helped define the how and why behind RAPID and how it would be used in a team that wants to focus on both, the product and the customer.
Maturing from a StartUp to a StartedUp culture – Series Part 5
People growth – Old blood vs New blood
I wrote my first post here on Jan 23 2011 and that post was titled “Startups – importance of your team“; Its been a little over 2 years since I wrote that post.
Most of us work 5 days a week, putting in about 8 or so hours a day (we will stick to the average/norm here). We come back home in the evening to spend anywhere from 1 to 4 hours with our family/friends.
When friends and/or acquaintances form a startup, the long hours and the close working relationship build on existing relationships and everyone at the startup works as a “family”; but what happens when there are no existing relationships? or what happens when you already have a family and someone new tries to come in? Wouldn’t it be awkward if you were out with your family/friends and a stranger joined your group and just hung out? would you be your self? most wouldn’t.
So how do you take an existing family (a started up culture) and add newer members to it? How do you mix the two so that you do not end up with friend circles?
I have 4 simple attitudes/behaviors that I build my base on:
“We are not that different”.
The new member see’s a whole new planet, different people, cultures, processes, jargon, etc. The first step should be to look for similarities between what they know and what they should know. For my teams I use a buddy system and its usually the previous newest member who buddies up with the new member. They go over materials, documenting anything new that might come up, go for lunch, talk about process, go through the who’s-who, engage the new person in conversations with the other team(s); they try to get to know this person as if they were dating each other.
“We got this, lets work on it together”.
How do you start work? where do you start? who do you ask? Scary questions for someone looking under the hood of something they do not understand. Here is where the buddy comes in again; during stand ups and sprint planning the buddy might offer “we can work on this together”, or someone else on the team might say “hey this is a good problem for me to show you how xyz works, and we can solve it”… they get the knowledge, they figure out how to start, they experience the process and they know how to close it. Build trust and accountability.
“Your team mentioned that you are catching on so quick, what can we improve?”
Over communicate reinforcement of team acceptance, ask for ideas on what can be improved, engage the new member; engaged employees have ideas and feedback that they want to share, things they have questions about.
“You are doing great, let me share my vision on how you play an important role to the team”
Setup a growth plan that’s challenging and communicate that it may be challenging and track to it. I like to plan for the 1, 3, 9, 12 and beyond and use data obtained directly or through peer feedback to gauge fit; if there is going to be tissue rejection, you need to act fast and figure out what you need to do to make it work successfully.
These 4 steps get you on track but you will still need to build additional on-boarding processes (around material and core knowledge ) that will grow the employees product knowledge. Its also important to keep your existing members in mind when you optimize culture as you want to grow the existing employees as well and not just the new ones.
At the end of the day it helps if we recognize that the teams we work with are more than just “Random people”; they are people we spend several hours with, they are friends, people we trust, can openly collaborate with and people we want to continue to work with.
When one finds a team they can work with for the rest of their life and can call family, its no longer “work”…it’s just a large friends & family gathering where they just happen to be working on something together and having fun.
We should all build and be part of such teams.
Maturing from a StartUp to a StartedUp culture – Series Intermission
People?
Yes!
Product?
Hell Yes!!!
Process?
Boooooooo!
Is that what comes to your mind when someone mentions “process”? For many that’s a “Yes!”… “We don’t need no stinkin process; we just want to work”
“Process is just a book definition of something”, “its boring stuff”, or “Theory that doesn’t apply to the real world” are some of the phrases I have heard people use in disgust to define what process is; and in a past life someone used a “process is something that doesn’t apply to a startup or startup culture” on me….
“We care about people”
“We care about product”
“We only care about people and product”
..but what about process? why does process not get any love? What is it about process that makes people cringe? If process is evil, why is it that many methodologies (based on research and metrics) focus on the importance of all three (“People”, “Product” and “Process“)?
Process is everything that people and product are not.
Process:
- is culture and a shared understanding,
- it’s how your teams work and collaborate.
- it’s how you measure performance,
- its how you innovate, grow, plan and deliver product,
- it’s how you engage and grow people,
- Its more than ISO certification…
- its a lot more than this
Life is a process that’s filled with people and products
(among other things)

Dilbert – Scott Adams Inc.
Maturing from a StartUp to a StartedUp culture – Series Part 4
The takeaway from the previous post on KPI and metrics was that we should proactively monitor process and optimize as needed; just because it worked when you were a startup does not mean it will work when you are “startedup”, you will need it to scale and by capturing metrics and KPI’s you will be able to perform analysis when/if things go wrong. This however does not mean that you need process for the sake of having process or that you should focus on process over people; agility is important and being lean goes a long way.
The chicken and egg problem: What came first, the chicken, or the egg?
You have great team(s) and you have great product(s). Your team(s) is/are at capacity enhancing and maintaining the current product(s), but you need to create more product(s). In order to grow product(s) you need to add more people but these people need to be grown as well. Hiring people and not growing them will make product growth challenging as there will be a longer ramp up time or will disengage and leave (or you end up with an us vs them culture); and redirecting your current team to grow people rather than the current products will grow the new hires at a rapid pace but your current products will stop growing, what do you do? going back to the chicken and egg problem, I think in the long scheme of things it is irrelevant what came first; what is more important is the realization and existence of the chicken and egg, or the “idea” of a chicken and/or an egg, and that you need to ensure that the cycle continues, chickens give eggs and eggs (eventually) give chickens.
Single points of failure (Single Threads)
As engineers and architects we focus on identifying single points of failure within architecture; as managers we need to identify single points of failure within team members, processes and tools. Ask yourself, if I was to randomly start pulling people out (pto, resignations, etc) what would be the impact? Would we still meet delivery? Do we lose key subject matter experts? Most of the time people end up becoming single threads because there are many hats to wear and things need to get done; documentation and knowledge transfer becomes a “will get to it” task that many never get to.
Single points of failure and knowledge silos end up becoming a real impact to growth when you bring on new hires who need to be brought up to speed and grown because the same resources that need to help grow others are already busy with their existing work. Not only does it impact growth, it also negatively impacts collaboration and team culture, when people do not grow they disengage and this causes further issues. As you grow from a startup company with a smaller team to a “startedup” company with a larger and growing team, your single points of failure can grow and teams/members can get frustrated as they get pulled from different directions.
A few simple approaches to reducing and/or eliminating single points of failure are:
- Focus on collaboration and knowledge sharing among teams (culture), the more people share what they learn the more people know.
- Work-load for single threads can be split between product development and people development.
- On-boarding programs and training documentation can be built as part of a product backlog.
- New hires can be paired with senior resources to create mentor-ship and knowledge transfer programs.
Each organization is different and each has its unique attributes that require a solution or several approaches that solve the problem for that specific organization; a silver bullet approach doesn’t really work.
Summary
- To grow new product(s) outside your current capacity you need to grow team(s).
- To grow new team(s) who will grow new (products) your current team(s) can be impacted.
- Your current team(s) can end up becoming single threads and/or single points of failure.
- Recognize that this can become a problem.
- Focus on culture, collaboration, knowledge transfer, documentation, etc. so that the impact to the current team(s) and product(s) will be minimal and your new team(s) will rapidly grow and be engaged.
Maturing from a StartUp to a StartedUp culture – Series Part 3
Several years ago I had a Volvo (88 760 GLE) and one day I noticed little streams of smoke from under the hood every time I would get back home; I had little experience with cars back then so I took it to a friend’s dads shop. I should have probably left when I got there because there was a customer yelling at him for messing up his beetle and charging him extra to fix it; apparently he put some hoses on wrong and then had to redo the work, I wasn’t there for the whole story, just the last 20 minutes of it and then the customer drove off.
My friend’s dad asked me to start my car and pull up next to him and leave the car running. He popped the hood and started to look around, he checked the hoses, looked at the pump, lines, drove it around, several hours passed by… he went from suggesting that there was coolant leak, to transmission leak to radiator oil leak… several more hours passed by as he came up with theories and looking at things… after being there for about 6 hours I decided to stick my head in and look at the engine block near the side where I told him to look and thought the smoke was coming from. Sure enough, just as I looked, I saw bubbles near the engine block’s cover, pointed it out to him and he said “ah, it’s loose! oil is getting out”; brought over his tools, tightened it and the problem solved.
I had been there for 7 hours, he wasn’t the type of guy who would say “this is my son’s friend, I am going to help him out”; he was a business man and to him I was a customer. I was upset with him for wasting 7 hours of my time; but what was really on my mind at that time was “how much will these 7 hours cost me?”, especially since he had a sign posted that had “Service hour rate: $45/hr” in big letters…. I will get back to this later in the post.
KPI and metrics
Man hours, hours, T-shirt size, story points, etc are measurements. I will try my best to not go down a rabbit hole with scrum, story point’s vs hour estimates… I will not! and hopefully I won’t lose my original messaging in all of this. Let’s start with this; at some point or the other, the focus and bottom line for a company will be “shipping product” against a “delivery schedule”. People, process, culture, story points, hour estimates, etc. will eventually stop existing if the “startedup” company cannot ship product and closes down (the focus here is shipping product according to other peoples expectations, i.e investors, C-suite, etc). With this at the back of our minds let’s continue on.
Story points are a measure of risk and/or effort and/or complexity (the and/or is there for the ones who disagree that story points do not measure complexity and/or risk).
Work/Task estimates are hours (usually) it takes to complete a task (with risk, complexity and effort already factored in).
Some argue that story points are just a block of time that provide the developers with padding; some argue that story points and hour estimates are not the same; some argue that time estimates need to be detailed and you should only use blocks of time (i.e. story points). I am not here to argue about any of these.
If you look at what part story points and sprints play: Story points (representing stories) go into sprints and sprints are boxed in time; at the end of the day, we are basically fighting for time. Others (Non-developers) usually want to know “how long will it take”, “when will it be done” because they need to set schedules, communicate to others, but (most) developers just want to work 🙂
How can I tell you how long it will take to fix when I have not even looked at the code; code that someone else wrote years ago!
When you have your team of 10 who have been working on a project (or two); the story points, velocity charts and estimations work out great. The team of 10 will negotiate points and the best suited person will do the work; everyone starts getting a good idea of what others and they themselves can do with improved accuracy (and velocity).
What risk can come up when you throw in 65 new hires and 2 new projects?
One thing that can happen is that the wrong person can get the wrong story; it is also possible that the new team may incorrectly estimate story points.
This happens or can happen because it takes experience and familiarity to get both (story point estimates and story assignment) of these right. Let’s say everyone is working on their tasks for a sprint, there is 1 story (something to do with SSL) remaining and it MUST make the sprint (which closes sooner than the story can be worked); the one developer available knows NOTHING about SSL, and a simple change measured as 2 story point remains, there is a developer on the team who knows about SSL but she is already working on a different feature that requires her knowledge on encryption.
Why did this get set as 2 story point when it was obvious to the team that there was risk? Rather than negotiate for 5 points the team settled for 2 because they expected the more senior programmer to have a better idea of how many story points it would take; the senior programmer saw no problem with 2, because in the past, her team was comfortable with it being 2. Repeat this several times, and you have a pattern; how do you break this pattern? or how would you even recognize this pattern? How would someone have suggested 5? How do you further refine estimating story points so that its not just based on gut, experience or familiarity? You start building and tracking additional KPI’s/metrics. Velocity and Burn Up/Down charts are common KPI’s that most use, you need more to help fish out patterns and gaps.
I think it’s important to acknowledge that in a true scrum setup (a perfect world, which is possible) these things may not happen (or happen rarely); if something doesn’t make a sprint, it moves to the next, but in most (all) of the places I have worked at, true scrums do not exist, shit happens and you cannot NOT make the dates; unless the team pulls together, works OT and possibly burns out (if it keeps happening).
As many others do, I like to base my estimation on experience and collectively agree with a team; but wouldn’t it be easier if there was another set of metrics that provided extra assurance or a reality check? i.e. historical data. Either metrics against tasks or metrics against similar stories. i.e. a story around “user login” averages to be a 4 point story based on previous similar stories; a task to “check credentials against db” takes 2 hours? The metrics can be captured after sprints/projects are done in adhoc meetings or release review meetings the data would be used for new hires, for times when things are under/over estimated. New hires and others could use this data to help estimate and understand gaps between what it takes on average and how the teams perform; the KPI’s would further detail teams health…
Going back to the Vovlo; I was waiting at his desk while he put his tools away, then he walked back to his desk, opened up a book, flipped pages to a section that read “Diagnostics”, found a line item for “Oil Leak” and sub-item “Gasket”, and said “2 hours, so you owe me $90 for fixing the problem”. Even though he spent 7 hours on it, he charged me for 2 because that’s what the book that had metrics for that type of service said it should take.
The Volvo example is important to me because it identifies performance issues; i.e. he should have done it in less than 2 hours if he was a good mechanic because that’s how long it takes on average; he should be asking himself “why did it take me more than 3 times as long and how can I do this better” because that’s what we would use similar development metrics for. “I seem to always under estimate UX changes, I need to pay better attention”.
The example I used has so far revolved around a startup company of 10 growing to a startedup company of 65; let me use a different example: A software development boutique is agile and they have client projects captured in back to back sprints. There are account executives that double as product owners who talk to the customers and based on experience and some dialogue with a few dev leads, they estimate effort and agree to a schedule and budget. Once they are ready to start the sprint (for a new project) the dev leads will update the team and as soon as sprint planning (stories placed) is done they start rolling.
A few issues:
- The dev lead and account executive time-boxed the maximum amount of time it can take based on their meetings with the customer; there was no team review
- Account executives double as product owners; their stories aren’t reviewed by developers until the work actually starts since developers are already busy on other projects
- There is no room for scope creep; things cannot get thrown out since this is a client project, and it must meet a date
- When there is scope creep and because its boxed; resources will work over time and burn out since the cycle just repeats it self – regardless of what your story points are, they have to fit in the sprints.
You could point out that the issue here is that there isn’t team involvement with the original estimation (for the time box) but this is because of how the company chooses to operate, so you cannot change this. You could state that the issue here is that there will always be some sort of scope creep so you cannot expect a hard stop but this is also because of how the company caters to customers expectations and needs to operate.
I would argue that the issue here is that the account executives do not have a “rate book” or “performance history” for similar tasks/stories that can help them come up with better estimates and factor in complexity when needed. In addition to that, since this company is in a pattern of running over (and solving by having people work over time, every time) there should be some sort of analysis done after each project to come up with “mistakes made” or “lessons learnt” so that people can learn from the patterns and put out better estimates; there will be times where you cannot change the entire companies culture, so instead you need to look for what can be improved.
With focus on additional KPI and metrics; one can identify issues with process or gaps before they become a bigger problem; Don’t just stick with how things worked when you were a startup and expect things to continue to always be perfect once you start growing, when you are “startedup” you need to start looking at adding new KPI’s and measurements that will help the bigger team work better and scale.
Maturing from a StartUp to a StartedUp culture – Series Part 2
The Startup and the 3 P’s: Product, Process and People
I will not pretend to know everything about startups and startup culture, but I will list the reasons why startup culture is exciting, at least for me:
You meet great people, people who have ideas and want to try things, people who have passion and want to make an impact, people who will challenge you to do better. There is passion for working together as a team, passion for building trust within the team and passion for collectively making an impact in other people’s lives; or sometimes, passion for just making something happen – to create. There is passion for possibly creating something that could go big – disrupt everything, all built from the ground up with the teams sweat, blood and tears where everyone is high on adrenaline. Suits? Offices? As long as you are connected with your team and are working well together, those things don’t matter. There is no red-tape, or big top-down structures, everyone and anyone has access to all. Anyone can start working on anything, there are many hats to choose from; wear all. You don’t get bored as things are evolving and stay fresh, there are new ideas, old ideas, odd ideas; anything can change anytime.
At the end of the day, a startup is defined by its growth; when a startup doesn’t grow, it dies; it stops.
There can be several growth stages for a startup, and startups evolve; once they start growing they are now “startedup” and will hopefully grow exponentially. In a perfect world, the cultural values that made the startup fun would remain and in some cases they do (depending on where the growth has lead the startup) but there are times where the culture itself that helped the startup grow and evolve starts conflicting with what is needed to grow to the next level.
Product Growth
Let’s say you follow agile and you end up with iterations, planned work, release schedules and a clear pipeline of what needs to be built. This all worked great when you had 2 products and a team of 10; since you have grown, the expectations of what you can or will deliver have also grown. Some brilliant folks in your team have discovered 2 more products that should be added to your portfolio; how do you grow your current 2 products (since they have a feature and defect backlog) and also work on these 2 new products without increasing your team size, changing delivery for current products or burning out resources? Before you grew, you may have had your own expectations of when and how you would bring on these two new products; now that you’ve grown, others may have different expectations from you and your team(s). Maybe you say “we need more people”, which brings me to the next point
People Growth
With the growth of the startup, either through sales, funding or more investment and the need to create more product it is decided that you bring on more people, and you do. You end up facing the same issue, how do you grow people with the same 10 resources you had who are busy working the two existing products; some of the people you bring on may be self-starters and will figure everything out by themselves but what about the ones who don’t? So now you say “we need some process and automation to free up some of the manual work so that we can do more with the same resources”, which brings us to…
Process Growth
How do you focus on process and automation to free up time when the people you have are busy with supporting the existing two products, or are supporting the existing two products and are also trying to bring the new hires on-board?
A part of me says that the above three growth challenges are not really challenges and that they are part of what it means to be a startup culture and are expected. However; there are a few by-products that the 3 P’s create that can become toxic, stop growth and hurt the culture if they are not accounted for when trying to grow.
The Frat party & the first team
The first team consists of the people that built the startup; it was their teamwork and effort that made the startup grow; anyone who comes later is an outsider and “we need to be careful about who we let into our frat party” (once upon a time I lived on frat row). This one is not intentional, but when you work closely in teams and blur the line between friendship and co-workers, you end up creating an inner circle and make it challenging for an outsider to easily integrate and feel welcomed. This by-product is a blocker for People growth.
The golden simple process
At some point there was predictability and little chaos in what all needed to be done (smaller team, less products) so everyone starts expecting things to always be perfect. Even though you have grown, you have kept your process simple and did not optimize for KPI’s and other metrics that can help with predictability, complexity, risk and estimation. There will be times where things change, dates get reset and/or product scope creeps. If you had built a roadmap of what releases when, had committed the teams to that and put all these releases with their iterations back-to-back (because of all the product that had to get pushed out to show growth and maturity) and dates or requirements change on you (usually not for the better) the team and its happy culture will get disrupted as it will take effort to get things back on track; when/if this happens all the time, it gets hard to get away from the domino effect and people burn out, get disengaged and/or leave. This by-product is a blocker for Process growth.
Single threads
When you were small, everyone knew what everyone else was doing, everyone shared and individuals had their skillsets. Now you have grown, 2 months ago you were 10 people, today you are 75, the 65 newer ones don’t understand the code base or the original design, there is some good documentation but they need more information and there are 3 key people who know different things about the original products; original products that you want the new 65 people to work on so that the first team can work on the two new ones; how do you distribute the knowledge known by the 3 key people, make them available to the 65 and allow the 3 key people to focus on their new projects? If they are constantly being pinged by others and cannot get their work done; their sense of accomplishment doesn’t scale much; especially if you did not plan for them to set time aside and help others. This by-product is a blocker for Product growth.
Each blocker is situation (just like leadership) and can be solved; we will examine and solve for each, before we move onto other “StartedUp” culture challenges. The next post goes into process KPI’s and metrics – addressing the golden simple process blocker.
Maturing from a StartUp to a StartedUp culture
The content for this discussion is several pages long so I will release it in posts as a series.
Introduction
A couple of weeks ago I had interesting discussions with a software lab focused on mobile tech out in the Boston, MA area. Ideas were exchanged, we spoke about different issues that impact teams, growth, product, process and discussed different ways they could be solved.
After the dialogue, reflecting back on the content and looking for a root cause or pattern I realized that this wasn’t the first time I had discussed or worked on solving these type of issues; growing pains, single threads, lack of process, maturation are just some of the terms used to describe the root cause and in most cases its all of them as they mean the same thing and to me that is “growing startup culture”
A startup company or start-up from http://en.wikipedia.org/wiki/Startup_company
A startup company or startup is a company, a partnership or temporary organization designed to search for a repeatable and scalable business model.[1] These companies, generally newly created, are in a phase of development and research for markets. The term became popular internationally during the dot-com bubble when a great number of dot-com companies were founded.Lately, the term startup has been associated mostly with technological ventures designed for high-growth. Paul Graham, founder of one of the top startup accelerators in the world, defines a startup as: “A startup is a company designed to grow fast. Being newly founded does not in itself make a company a startup. Nor is it necessary for a startup to work on technology, or take venture funding, or have some sort of “exit.” The only essential thing is growth. Everything else we associate with startups follows from growth.”
And from the same source, a startup culture
Startups utilize a casual attitude in some respects to promote efficiency in the workplace, which is needed to get their business off of the ground. In a 1960 study, Douglas McGregor stressed that punishments and rewards for uniformity in the workplace is not necessary, as some people are born with the motivation to work without incentives.[11] This removal of stressors allows the workers and researchers to focus less on the work environment around them, and more at the task at hand, giving them the potential to achieve something great for their company.
This culture has evolved to include larger companies today aiming at acquiring the bright minds driving startups. Google, amongst other companies, has made strides to make purchased startups and their workers feel right at home in their offices, even letting them bring their dogs to work.[12]The main goal behind all changes to the culture of the startup workplace, or a company hiring workers from a startup to do similar work, is to make the people feel as comfortable as possible so they can have the best performance in the office.
This is what most of us understand startups to be; but I would argue that startup cultures do not only apply to a new or young company (a startup) or that the culture is inherited through acquiring a startup; applying the culture and model that exist in a typical startup one can “build startup culture”.
If startup culture is a “must have” then how can there be any issues with that culture? To clarify, in my opinion startup culture is great, they build great teams, focus on product, have a great culture and are fun to be in – and I respect and thrive in them; you start running into issues once the startup has started-up and you need to scale three core P’s: people, product and process. For me, the key is using teamwork and relying on your peers to figure out how to scale all three at the same time while everyone is busy with their other workload.
The next post will outline some of the end-products of startup-culture that should be addressed/changed in order for the startup to mature as it goes from being a startup to started-up culture
Rapid Agile – Real-time Actionable Prioritized Individual Delivery
So what does come after Scrum/Kanban/Agile?
The evolution of the SDLC continues as expected and if you look at the trend, the focus has been to get things done quicker – Rapid.
Andy @ Assembla calls it Scalable Agile and has great content explaining the concept behind it; I call it Rapid – Real-time Actionable Prioritized Individual Delivery, or Rapid Agile and the basics around the process are very similar. The focus or goal is to prioritize individual efforts rather than a team sprint, act upon real-time feedback and deploy much quicker; often deploying new features and bug fixes several times a day rather than ever other week or so.
Case Study: Blank Label
At Blank Label when we were much younger, we manually deployed whenever we wanted as we were trying to rapidly enhance and stabilize our offering. With every feature came a lot of bugs and it was usually the changes in usability that brought inconsistency in usability as we had limited resources and a lot of “to-do’s”. Eventually we settled on a 2 week delivery cycle but as we were attempting to find out who our customer was, we made some drastic changes only to see orders drop from several a day to almost none every week. We had no idea what of the 20 things we changed in the 2 weeks that killed it as A/B testing had told us that our sales would go up, not vanish.
Fast-forward many months – we saw that we had gone back to our old habits, but this time we had process and we were not disrupting things when we updated, we deployed to a staging server, tested things out there and then released to the live server. This still required manual builds and deployments, many times fixes just didn’t make it to the live system when issues were discovered because it required someone to build and upload…
Now fast-forward to yesterday – we now build the backlog in Jira and make use of green-hopper for their kanban board. We go through a to-do, doing, build and live workflow, where bamboo will automate code checkins and deploy with AWS ec2 to our staging server; once testing passes staging, the deployment to live is a simple click of a button and live is then refreshed.
For test, we have gone from 1-3 pushes to test per day to 5-8 pushes per day and for live will be going from one refresh per day to 2-3 refreshes. We still have a small team of developers, once this team grows we will probably see a large increase in pushes to test, but will probably maintain the 2-3 refreshes to live per day (depending on the functionality).
In the not so distant future, I will provide the development workflow process along with the tutorial to build all the Atlassian stuff that will get you to a rapid continuous integration, deployment and deliver model as I did not see a lot of solutions that focused on the .Net MVC3/4 Razor stack.
