Tagged: scrum
RAPID Agile: Customer Focus – Defect Management
Before we dive back into defining an approach that mixes Product and Custom focus, we should probably ask “How does one focus on the customer?”
In an ideal world there are no defects; but since there are, and customers expect them to be resolved, an ideal approach balances itself between being proactive and reactive; proactively resolve reported/discovered defects and appropriately manage escalations. On the surface, one focuses on the customer by making sure that the defects are fixed before a customer reports them and if a customer reports them, they are addressed promptly (top priority of course) and the customer is satisfied – below the surface, defect management and prioritization play an important role towards our customer focus as this tells us how soon we can (and will) actually resolve defects.
The list below doesn’t capture all possible approaches in resolving defects; it captures approaches that I have had some experience with (I recommend that you certainly do not try the first one):
Don’t resolve them- Push the defect to the original developer, or the developer most familiar with the functionality for resolution.
- Allocate time for the first available developer to pull a defect in and resolve.
- Have a defect duty rotation where a person (or team) resolves only defects for a time period
- Have a dedicated team for defect resolution.
- … Some other create ways to resolve reported defects..
Always push to most familiar
Pushing the defect to the most familiar sounds like a great idea and in many cases it is because the one most familiar would be able to resolve quickest and positively impacts customer experience. The issue with this approach is that the most familiar person might be involved with something that has a higher priority than this defect, or is out on PTO and would not be able to resolve for another 2 weeks. Let’s say it takes someone familiar with the code to resolve in 1 hour but takes someone not familiar with the code 6 hours. If the defect goes to the person currently tied up and is most familiar, the customer will have to wait a minimum of 2 weeks + 1 hour; however, if it goes to the person not currently tied up and is least familiar, the customer will have to wait a minimum of 6 hours. Being collaborative and available for the team may improve the turnaround time on average, but a hard coded “always send to the one who created it” may not be the best approach.
Allocate time to pull
Allocating time towards the end of an iteration, development or whatever, towards “defect resolution” allows the team to first get the scheduled work out of the way, and “if” there is time, someone may pick something up from the backlog of defects. The issue with this approach is that if the development cycles are fully booked (maybe there is a hard date) and there is any risk or complexity that might lead to developers putting in all they have to meet the delivery; defect resolution gets thrown on the back burner. In most cases where the approach is “allocate time to pull defects”, the unspoken rule is that new products come first, defects second – unless; where the “unless” is for escalations and chaos/fire-fighting instances. For agile teams, if the time allocated towards defect resolution does not change from sprint to sprint, then there is no impact to velocity; however, if the time allocation is not fixed the velocity can get impacted depending on how much time is spent on defect resolutions (usually hours) vs. features (SP’s)…. You could estimate defects in story-points but this can lead to additional issues that will need to be worked out… i.e. do you really want to hold a sprint back? etc..
Defect resolution duty rotation
For a given time (usually the span of a sprint) a developer within a team, or a whole team themselves will be on defect resolution duty; once the time span is over, someone else (or a different team) takes on defect resolution duty and so on. This helps cross-train and helps make everyone familiar with the code base. It can also help improving code quality since everyone is learning from everyone’s mistakes and provides a great collaboration platform; while it does have some great benefits it does introduce some challenges. A significant issue is that developers and teams lose traction as they switch focus from “new product” to “old product”; the interruption can cause a delay since the developer(s) will need to get back to where they were after the rotation is over. For organizations that have many teams or larger teams this may be less of a concern since the rotation might happen every few months; but even then, when it does happen it does have a negative impact.
Dedicated team for defect resolution
The thought on this one is that if there is one team solely focused on supporting “released software” (defect/engineering sustaining team) and other team(s) focused on creating “new software” (Feature teams) that you end up with a two-tiered development approach where both the product and the customer can be focused on. The feature (new software) team is rarely impacted by defects from the “live” world and they can always focus on delivering new product; the defect/engineering sustaining team is dedicated to resolving defects and is not tied up with new features. The issue with this approach is that no one aspires to be a “defect fixer”, developers want to “develop” new and innovative “features” (or at least I did); It is possible to make this work if more attention is given to down-time cross-training, root cause analysis, collaboration, role rotations, etc… (I have seen teams evolve this approach into a “defect resolution duty rotation” approach)
In addition to the above, there can also be hybrid approaches that mix various approaches, i.e. defect resolution duty rotation with an added “pager duty” where someone (not on defect duty) is on-call but in general there is no “incorrect approach”; however:
Any approach can become incorrect when developers are forced to accept an approach that they do not agree with (or understand).
Any approach that is going to be implemented should be discussed with the teams that will be implementing it, focus on and explain the “why”. When an approach does not work, try to adjust it or try something else!
“if the code repository is an “elephant” and new code is peanuts being fed to this elephant by the other guys, then I am always cleaning up after the elephant; who wants to be a shit cleaner forever?”.
RAPID Agile: Focus on Product and Customer by mixing Scrum and Kanban – ScrumBan
We are usually torn between building more “product” or satisfying the “customer”.
Prioritize Customer (maintaining product)
Fix and release to save the world
Prioritize Product (building more product)
Plan and build to a schedule
When you focus on product, you have a certain “amount” of product that needs to be built within a sprint (time box); you can plan for fixes by leaving some room for the defect backlog, but features come first – then come fixes, and the work is usually fixed where people know what they are working on for the sprint. In this scenario most will usually package after the sprint is over (test and release)
When you focus on customer, you have to fix and get the fix out the door ASAP. Priority is given to the most critical fix and/or customer and things will be packaged (test and release) as soon as appropriate and/or possible.
Some solve this by having a sustaining engineering team, but who really wants to only fix defects?; others use a mix of cross-functional or functional teams and adjust as needed, but this can be disruptive.
If you chose to “adjust as needed” (be agile) you will introduce some chaos every now and then but this can be minimized by having “plan of action”. How you adjust as needed and what type of “plan of action” you need also depends on what type of process you follow and what your focus is; is your culture focused on product? or is your culture focused on the customer? Depending on whom you ask (their role) within an organization, you may get different answers.
If you follow “Scrum” then your work queue is mostly “push” defined, where work is planned and pushed into a sprint/iteration before its worked on.
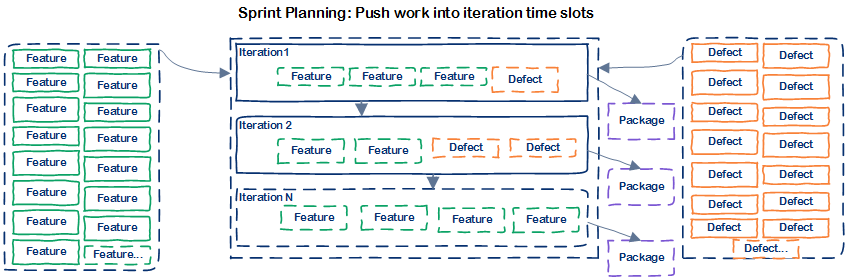
If you follow “Kanban” then your work queue is mostly “pull” defined, where work is pulled and worked on.

In an ideal world, one would have a process that allows the focus on both, the product and the customer. A process that allows you to “build what you say you will build” but also allow you to focus on “what is important right now”; such a process would mix Scrum and Kanban, giving you, ScumBan. The idea of a Scrumban is not new; there are books and many talks/posts regarding this. How Scrum and Kanban are merged together depend on the person who is cross-breeding the processes and what problem(s) they are trying to solve; I named my implementation “RAPID” for “Real-time Actionable Prioritized Individual Delivery”.
In my next post around RAPID, I will go over some examples that helped define the how and why behind RAPID and how it would be used in a team that wants to focus on both, the product and the customer.
Rapid Agile – Real-time Actionable Prioritized Individual Delivery
So what does come after Scrum/Kanban/Agile?
The evolution of the SDLC continues as expected and if you look at the trend, the focus has been to get things done quicker – Rapid.
Andy @ Assembla calls it Scalable Agile and has great content explaining the concept behind it; I call it Rapid – Real-time Actionable Prioritized Individual Delivery, or Rapid Agile and the basics around the process are very similar. The focus or goal is to prioritize individual efforts rather than a team sprint, act upon real-time feedback and deploy much quicker; often deploying new features and bug fixes several times a day rather than ever other week or so.
Case Study: Blank Label
At Blank Label when we were much younger, we manually deployed whenever we wanted as we were trying to rapidly enhance and stabilize our offering. With every feature came a lot of bugs and it was usually the changes in usability that brought inconsistency in usability as we had limited resources and a lot of “to-do’s”. Eventually we settled on a 2 week delivery cycle but as we were attempting to find out who our customer was, we made some drastic changes only to see orders drop from several a day to almost none every week. We had no idea what of the 20 things we changed in the 2 weeks that killed it as A/B testing had told us that our sales would go up, not vanish.
Fast-forward many months – we saw that we had gone back to our old habits, but this time we had process and we were not disrupting things when we updated, we deployed to a staging server, tested things out there and then released to the live server. This still required manual builds and deployments, many times fixes just didn’t make it to the live system when issues were discovered because it required someone to build and upload…
Now fast-forward to yesterday – we now build the backlog in Jira and make use of green-hopper for their kanban board. We go through a to-do, doing, build and live workflow, where bamboo will automate code checkins and deploy with AWS ec2 to our staging server; once testing passes staging, the deployment to live is a simple click of a button and live is then refreshed.
For test, we have gone from 1-3 pushes to test per day to 5-8 pushes per day and for live will be going from one refresh per day to 2-3 refreshes. We still have a small team of developers, once this team grows we will probably see a large increase in pushes to test, but will probably maintain the 2-3 refreshes to live per day (depending on the functionality).
In the not so distant future, I will provide the development workflow process along with the tutorial to build all the Atlassian stuff that will get you to a rapid continuous integration, deployment and deliver model as I did not see a lot of solutions that focused on the .Net MVC3/4 Razor stack.
